If your enterprise relies on a rapidly growing tech infrastructure, you’ll understand why a Site Reliability Engineer (SRE) has fast become an indispensable role in the IT industry that combines the world of software engineering and operations. The expectations of what an SRE professional will need to accomplish by the year 2025 will be exponentially intricate, with the huge breakthroughs in Artificial Intelligence, greater demands on organizations to move to cloud-based environments, and more complex security apprehensions.
But what skills will they actually need to adopt?
Future-ready SREs will need a diverse toolkit: deep technical knowledge within the areas of automation, infrastructure, and software development; the ability to work with new-age technologies such as Kubernetes and AI driven monitoring tools; and the soft skills to align with business units and other technology environments. Most of all, an organization will need their SRE professionals equipped for the future because they will no longer have the luxurious approach where the SRE will simply maintain available and scalable systems. Companies will need their staff equipped with the knowledge to adapt and learn because technology of tomorrow will carry requirements that an organization might not see yet
To better understand which skills an SRE professional will need within the coming decade, let’s take a deeper look at these skills and competencies.
What Is Site Reliability Engineering (SRE)?
A Site Reliability Engineer (SRE) is a professional who bridges the gap between software development and operations teams. Their primary role is ensuring that software systems are reliable, scalable, and efficient. SREs use software engineering techniques—such as automation, monitoring, and incident response—to prevent outages, maintain performance, and continuously improve system stability, even as new features and updates are rapidly deployed.
SREs are tasked with ensuring the uptime, reliability, and performance of hosting platforms, often through automation and monitoring.
While their respective responsibilities are closely aligned, there are notable differences. Much as a power dialer powerfully automates the process of making calls to hundreds of prospects for call center agents, DevOps refers to the overall automation of repetitive IT tasks in your entire infrastructure to minimize human effort and mitigate human error. And DevOps engineers deal with this process focussing on operating production environments.
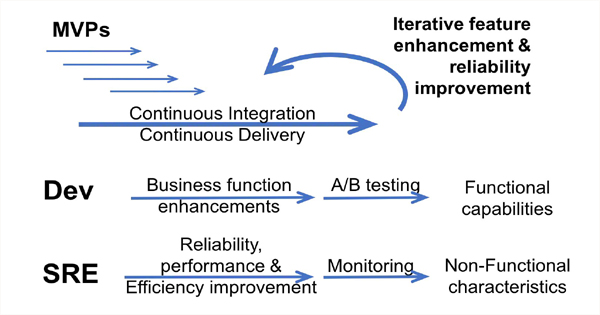
While SREs are concerned with the perspective of the reliability, resilience, and performance of this infrastructure as a whole, this involves a continuous analysis that seeks to anticipate performance bottlenecks while optimizing the infrastructure and workflows to ensure long-term sustainability.
What Are the Key Site Reliability Engineer Responsibilities?
While the role certainly varies depending on the projects and goals of the enterprise, an SRE usually plans and provides this infrastructure in the form of a platform, tools, and services that enable teams to view their metrics and gain visibility on their service workflows. Further SRE responsibilities can be broken down as follows:
- Gathering project goals and requirements from stakeholders
- Designing high-level representations of the whole infrastructure, including tools and workflows
- Providing businesses with updates about service health by implementing and monitoring metrics and KPIs that measure things like employee productivity across systems and services
- Performing analyses to identify root causes of issues and optimizing countermeasures by designing and building in alerts and on-call processes for contingencies
- Calculating the potential cost of downtimes and establishes strict Service Level Agreement (SLA) standards to improve system performance and balance availability
- Supporting management in analyzing how system performance affects business sales, revenue, and marketing functions
- Preparing input for updates across infrastructure, tools, and processes throughout the company
- Showing DevOps teams how to adhere to guidelines and instructions on required actions and system checks to minimize errors and incidents
- Creating and maintaining documentation that helps with monitoring.
Of course, given the uniqueness and specifics of different businesses, this is not an exhaustive list of an SRE’s responsibilities.
Essential skills for SREs in the realm of monitoring and observability include the ability to design and implement effective monitoring dashboards that provide at-a-glance insights into system health, as well as the skill to configure alerts that are both informative and actionable. A key aspect of this is the ability to set up and manage comprehensive monitoring solutions, define clear and measurable Service Level Objectives (SLOs), and accurately track the corresponding Service Level Indicators (SLIs) that reflect system performance against those objectives.
And although SREs may sound like an all-purpose solution to bridging the gap between development and operations teams, considering the cost in terms of salary, it’s worth reflecting on whether to invest in this role.
Site Reliability Engineer Job Description
Naturally, SREs will use a different mix of tools depending on your specific systems and the continuously improving products and services your business provides. That said, the skill set of an SRE includes a broad range of skills and competencies across development, DevOps, and system administration. Also, every Site Reliability Engineer should possess a range of essential soft skills.
Fundamental Technical SRE Skills
As a rule, SREs must be well-rounded and versatile as opposed to candidates with narrow specializations in tech. While they should be able to see the big picture, here are some essential SRE tech criteria:
- Knowledge and experience of major languages in software development such as Python, C++, or Java, which are crucial for automation and tool development
- In-depth knowledge of continuous integration, delivery, and deployment pipeline and tools like Gitlab
- Expert knowledge in major operating systems such as Linux OS capabilities
- Experience with major Cloud Platforms like AWS, Azure, and GCP is also frequently required, reflecting the prevalence of cloud-based infrastructures – – has become a fundamental requirement for Site Reliability Engineers.
- Solid grasp of DevOps concepts and best practices
- Familiarity with Monitoring Tools such as Prometheus, Grafana, Datadog, and Splunk is vital for ensuring system health and performance.
- Expertise and experience in IT troubleshooting and root cause analysis (RCA)
- Expertise in Container Technologies such as Docker and Kubernetes is increasingly important for managing modern, scalable applications.
Soft Skills
Having an SRE with the right non-technical skills and personality traits is just as vital in such a high-stakes role and with so many moving parts to consider. Beyond technical skills, we can’t emphasize the importance of these soft skills for SRE roles:
Performing Under Pressure
The ability to be well-organized and deliver in critical or high-volume production environments is essential.
Business Analysis
Just as savvy businesses might choose to adopt a .ae domain to benefit from the rising international profile of the UAE, for example, SRE must embrace such a business-centered approach. One that incorporates cross-functional metrics, thus avoiding a narrow focus on system optimization and gearing teams toward improved outcomes for the business overall.
Problem-solving
SREs should have strong problem-solving abilities to diagnose and resolve complex issues, work out the causes, and implement solutions.
Communication Skills
In addition to fluency in technical communication, SREs should also be skilled in communicating their ideas to management and securing buy-in from stakeholders for future projects, such as the pressing need for the introduction of the best video conferencing solution. Given the collaborative nature of SRE, the ability to work effectively within and across various teams, including developers, operations staff, and security engineers, is crucial for aligning on objectives and maintaining smooth workflows.
Educational Background
In terms of formal education, most companies typically require candidates to possess a Bachelor’s degree in Computer Science or a closely related field. Also, while not always mandatory, holding relevant Technical Certifications such as those in SRE, specific Cloud Platforms, DevOps practices, or Kubernetes administration is often recommended and can significantly enhance your candidate’s profile.
Employers seeking to hire site reliability engineers highly value practical experience in areas such as Linux/Unix administration, scripting with languages like Python or Bash, working with cloud platforms, utilizing containerization and orchestration technologies, implementing monitoring and observability solutions, understanding networking fundamentals, and leveraging CI/CD tools.
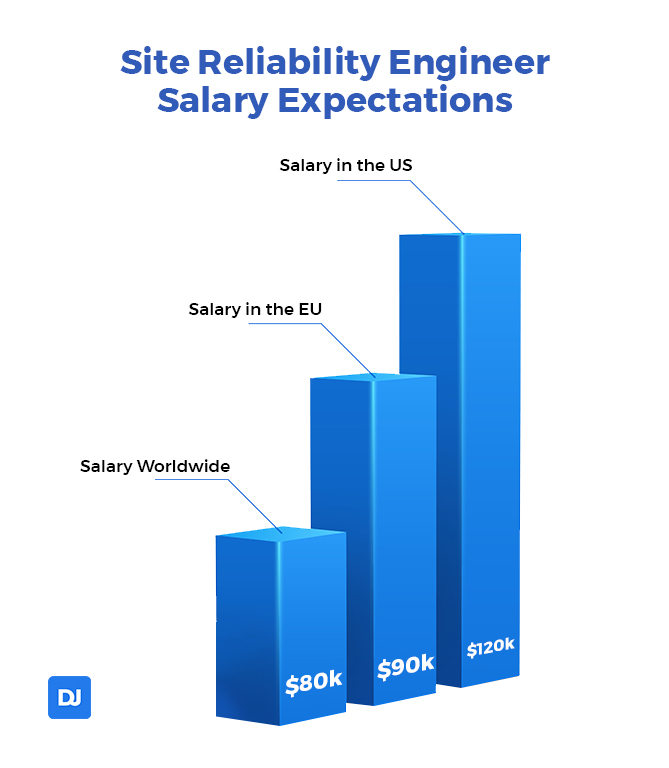
Site Reliability Engineer Salary Expectations
Here’s a quick glance at SRE salary ranges around the world:
- On average, the SRE salary worldwide is roughly $80k
- In the US, the average SRE gets paid around $120k
- In the EU, the average SRE earns about $90k
To Summarize
The essential skills for Site Reliability Engineering in 2025 are multifaced, and both technical and soft skills are a must. Continuous learning and a proactive approach to adapting to the ever-evolving SRE landscape will be crucial for professionals in this field to remain effective and relevant in the coming year and beyond.
SREs are becoming integral to the long-term sustainability of many organizations. Since the role of SREs is demanding and the expertise a rare hybrid, get in touch with us to find you that unicorn. We have more than 15 years of experience in the tech recruitment industry and are here to help you hire a site reliability engineer.