The later you catch a mistake or bug, the more exponentially expensive it is to fix. According to Boehm, if a team makes a wrong software architecture decision during the design phase, the cost to correct it in production reaches up to 100 times greater than if it had chosen correctly. This is the mathematical basis for why teams spend three years fighting against the code.
That’s what software architecture patterns solve. These patterns are battle-tested structural blueprints designed to prevent teams from reinventing the wheel. Your architectural choices directly define your company’s structure, your communication overhead, and the exact candidate profiles you must hire.
This guide analyzes the relevant software architecture patterns in 2026, exposes their nuances, and outlines what each pattern demands of your recruitment strategy.
What Is a Software Architecture Pattern? A software architecture pattern is a blueprint that defines a software system’s structure. It establishes the concrete subsystems, their explicit responsibilities, and the immutable rules governing their interactions. Architecture patterns dictate the system’s behavior, deployment constraints, and the application’s scalability.
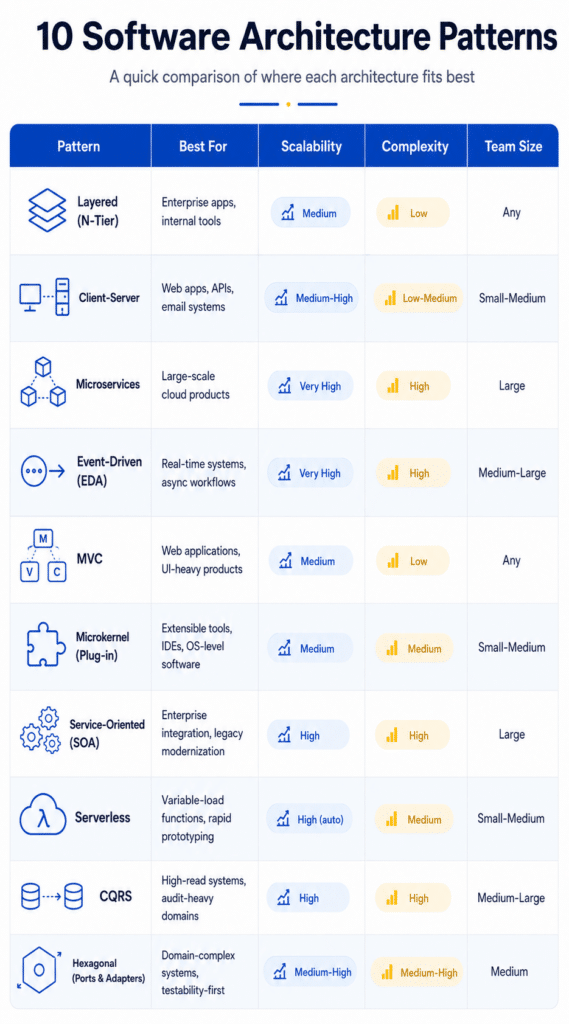
The 9 Software Architecture Patterns at a Glance
| Architecture Pattern | Best For | Technical Complexity | Scalability | Key Talent Profile Required |
| Layered (N-Tier) | Standard enterprise CRUD; low-to-medium complexity applications. | Low | Vertical | Generalist Full-Stack Engineers |
| Model-View-Controller | Web applications with synchronous, user-centric request-response cycles. | Low | Horizontal (Web tier) | Product-Focused Web Developers |
| The Modular Monolith | Growing applications want velocity without operational microservices tax. | Medium | Balanced | Strong Domain-Driven Design (DDD) Experts |
| Microservices | Massive, multi-domain enterprises with independent scaling requirements. | High | High (Granular) | DevOps/SRE & Distributed Systems Engineers |
| Event-Driven (EDA) | High-throughput, asynchronous streaming and real-time data processing. | High | High (Throughput) | Data Infrastructure & Event-Streaming Experts |
| Hexagonal (Ports & Adapters) | Core business logic that must remain completely decoupled from third-party APIs/DBs. | Medium | Codebase Longevity | Advanced Software Architects |
| CQRS & Event Sourcing | Complex domains with highly asymmetric read/write ratios or audit compliance. | Very High | Asymmetric | High-Seniority Backend Engineers |
| Serverless | Highly variable, unpredictable workloads; rapid MVP deployments. | Medium | Auto-Scales instantly | Cloud Native / Serverless Specialists |
1. Layered (n-tier) Architecture
Layered architecture is the most widely used pattern in enterprise software, and for good reason: it’s intuitive, well-documented, and works. The system is divided into horizontal layers, typically Presentation, Business Logic, Data Access, and sometimes a separate Persistence layer, where each layer only communicates with the one directly below it.
This pattern is the most common among software architects due to its methods of structuring software applications. This software architecture offers a clear separation of concerns that enhances maintainability and scalability, and a standardized interface that ensures that layers are loosely coupled, making the system more flexible.
This software architecture works well for most engineering teams. It maps perfectly to standard full-stack generalists. You do not need specialized infrastructure engineers; mid-level developers can navigate this codebase easily because its boundaries are predictable and linear.
How it works: Requests flow top-down through the stack. The UI layer handles display and user input; the business logic layer applies rules; the data access layer reads and writes from storage. Each layer has a defined contract with the layer below it.
Pros
- Easy to understand, onboard new developers, and maintain
- Separation of concerns makes individual layers testable in isolation
- Changes in one layer (swapping a database, for example) have minimal ripple effects
- Well-matched to parallel team development; frontend and backend can move independently
Cons
- Performance overhead from requests passing through multiple layers, even when only one layer needs to act
- Rigid when you need cross-layer interactions; the “sinkhole anti-pattern,” where requests pass through layers that do nothing
- Doesn’t scale as elegantly as distributed architectures under high load
Best for: E-commerce platforms, banking applications, content management systems, and any enterprise application where clarity and maintainability matter more than raw scalability.
2. Microservices Architecture
Microservices is the pattern that everyone is either building toward or recovering from. Done well, it’s the architecture that allows Netflix to deploy code hundreds of times per day without taking down the service. Done poorly, it’s a distributed monolith with network latency, a nightmare of service dependencies, and an ops team stretched to its limits.
The pattern breaks an application into a collection of small, independently deployable services, each responsible for a specific business capability and communicating over APIs or messaging queues.
How it works: Each service owns its functionality and its data store. Services communicate via lightweight protocols (typically REST, gRPC, or an async message broker). An API gateway typically sits in front, routing external requests to the right internal service. Common sub-patterns include the Aggregator pattern, the API Gateway pattern, the Saga pattern for distributed transactions, and the Circuit Breaker pattern for fault tolerance.
Pros
- You can scale services independently; for example, scaling the checkout service without scaling the catalog service
- Teams can develop, deploy, and own services autonomously, using whatever technology stack fits best
- Fault isolation means a failure in the recommendation engine doesn’t take down checkout
- Enables high deployment velocity when organized correctly
Cons
- Operational complexity is significant; you need robust monitoring, distributed tracing, and service mesh tooling
- Data consistency across services is hard; eventual consistency requires deliberate design
- Network-introduced latency between services must be managed
- The organizational overhead is non-trivial, and Conway’s Law applies; your architecture will mirror your org structure
Best for: Large-scale cloud-native products, high-velocity engineering organizations, streaming platforms, and financial services that need independent scalability per domain.
3. Event-Driven Architecture (EDA)
Event-driven architecture is built around one idea: components don’t call each other; they react to things that happen. An event is a record that something occurred (a user placed an order, a sensor detected a temperature change, a payment was processed), and any component that cares about that event can subscribe to it.
Instead of services calling each other synchronously via HTTP, components publish events to asynchronous message brokers (Apache Kafka, AWS EventBridge, RabbitMQ), and interested services consume these events asynchronously.
This decoupling is its superpower and its complexity. Systems can grow to an enormous scale because producers and consumers don’t know about each other. But tracing what happened and why requires instrumentation that most teams underestimate
How it works
An event is generated by a producer, indicating a change in the system’s state or the occurrence of an action. The event is broadcast through an event channel, ensuring that it is communicated to interested parties without coupling the producer directly to the consumers.
For example, when a customer purchases an item, the Order Service publishes an OrderPlaced event to a message broker like Apache Kafka, RabbitMQ, or AWS EventBridge. The Inventory, Billing, and Notification services consume that single event asynchronously at their own pace.
Pros
- Since components communicate through events, they do not need to be directly aware of each other, reducing dependencies and increasing modularity.
- EDA can easily scale to handle high volumes of events and processes.
- New components can be added to the system to listen for and act on events without modifying existing components, facilitating easier updates and expansion.
- The architecture enables real-time processing and responsiveness, as consumers react immediately to events as they occur.
Cons
- Tracking the flow of events and debugging can be challenging in a distributed event-driven system, requiring robust monitoring and logging tools.
- Managing a large number of event types and ensuring they are correctly understood and handled by consumers requires careful design and governance.
- Ensuring consistency across the system, especially in distributed environments, can be difficult when events are processed asynchronously.
Best Uses
EDA is widely utilized in modern distributed systems.
- Stock trading platforms
- Asynchronous systems
- Reactive user interfaces
4. MVC (Model-View-Controller)
MVC is the pattern that most web developers learn first, and it remains one of the most practical architectural choices for UI-heavy applications. It divides the application into three interconnected components:
- Model: Manages data, business logic, and state
- View: Handles display and user interface
- Controller: Receives user input, updates the Model, and determines which View to render
The Architectural Nuance
MVC is related to major monolithic web frameworks like Ruby on Rails, Django, and ASP.NET Core. The biggest danger teams run into is the “Fat Controller” or “Fat Model” anti-pattern, where business logic quietly piles up in one layer until the codebase becomes a tangled, hard-to-maintain nightmare that no one wants to touch.
- Ruby on Rails: Rails easily slips into the “Fat Model” trap due to ActiveRecord’s convenience, typically requiring service objects or concerns to offload business logic.
- Django: Django developers often overstuff views or model managers, eventually relying on forms, signals, or dedicated service layers to separate business logic from data access.
- Spring MVC: While Spring’s strict layering prevents bloated controllers, it frequently results in massive, multi-thousand-line @Service classes that absorb far too much responsibility.
- ASP.NET Core: ASP.NET Core commonly leverages the MediatR pattern to keep controllers lightweight by routing commands and queries through dedicated handlers.
Pros
- Clean separation between data, display, and logic makes the codebase navigable
- Easy to develop and test each component independently
- Widely understood; onboarding is fast, documentation is abundant
- Well-matched to the request-response cycle of web applications
Cons
- The Controller can become bloated (“fat controller” anti-pattern) when too much logic accumulates there
- The tight coupling between View and Controller makes it harder to separate purely front-end and back-end teams on complex projects
- Not ideal for highly complex domains where business rules extend beyond what MVC cleanly models
Best for: Web applications, content platforms, admin interfaces, and any product where rapid development and a well-understood structure matter more than domain complexity.
5. Microkernel (Plug-in) Architecture
The Microkernel pattern splits a system into two distinct parts: a minimal, stable core and everything else. The core does only what the system fundamentally needs to run. Every additional capability lives outside it, implemented as a plug-in that attaches at runtime.
If you’ve ever added a VS Code extension, installed a Jenkins plugin, or configured a WordPress plugin, you’ve used a product built on this pattern. The editor, the CI server, and the CMS; in each case, the product ships a lean core and lets extensions carry the weight of feature differentiation.
How it works
The core defines the interfaces, lifecycle hooks, and shared services that plug-ins can use. When a plug-in registers itself, it declares what it needs and what it contributes. From that point, it can be added, removed, or updated independently without touching the kernel. Plug-ins don’t talk to each other directly. Communication flows through the core’s defined interfaces, which keep dependencies explicit and contained.
This is what separates a microkernel from just a system with modules. The boundary isn’t organizational. It’s enforced. The core doesn’t know what plug-ins will exist at build time, and that’s intentional.
Where it gets hard
The interface contract between core and plug-ins is the most consequential design decision in the entire architecture. Get it wrong, and you’re in trouble fast. Once plug-ins are built against an interface, changing it means breaking every plug-in that depends on it.
This is why VS Code’s extension API has areas that feel conservative to the point of being frustrating. The team is managing a surface area that tens of thousands of extensions rely on. Versioning helps, but it adds its own maintenance cost.
Performance is the other honest tradeoff. The abstraction layer between core and plug-ins introduces overhead. For most applications, it’s negligible, but in latency-sensitive paths, it’s worth measuring rather than assuming away.
Governance is the third. A mature plug-in ecosystem is a product in itself. Discoverability, compatibility signaling, deprecation policy, security review for third-party plug-ins; these don’t come for free, and teams routinely underestimate them when they first adopt the pattern.
Pros
- New features ship without touching core code, which keeps the core’s blast radius small
- Plug-ins developed for one kernel can be reused across any system that shares the same interface contract
- Feature releases decouple from core releases, so teams can move at different speeds
- The core stays narrow enough to be well-tested and reliably stable
Cons
- Interface design is a one-way door: a poorly designed core API becomes permanent technical debt the moment external plug-ins depend on it
- The abstraction layer adds overhead that compounds as the plug-in count grows
- Running a plug-in ecosystem requires governance work that most teams don’t budget for upfront
Best for: IDEs and developer tools, operating system-level software, extensible SaaS products, and any system where feature variability is a first-class requirement.
6. Service-Oriented Architecture (SOA)
SOA is often dismissed as “microservices before microservices got good,” which is reductive. The two patterns share a core idea: organize functionality into discrete services. However, they make opposite bets on where intelligence should live. Microservices push logic into small, autonomous services and keep the communication layer dumb.
SOA puts a capable, centralized broker in the middle and lets services stay relatively coarse-grained. That’s not a flaw. For a large enterprise integrating 40 systems built across three decades, a smart broker is often exactly what you need.
SOA remains the practical choice when the problem isn’t greenfield design, but getting heterogeneous systems to talk to each other without rewriting any of them.
How it works
Business capabilities are exposed as services with standardized interfaces. Historically, that meant WSDL and SOAP; most modern SOA implementations use REST or even event-driven messaging. The Enterprise Service Bus sits at the center, handling routing, message transformation, protocol translation, and orchestration. A downstream application doesn’t need to know that the inventory system speaks one protocol and the ERP speaks another; the ESB absorbs that complexity.
Services are designed to be reused across the enterprise, not owned by a single team or product. That’s a deliberate architectural choice, and it’s what distinguishes SOA from a loose collection of internal APIs.
Where it diverges from microservices
The ESB is the clearest dividing line. In microservices, a message broker or API gateway is kept thin. It routes, but it doesn’t think. In SOA, the ESB is expected to do real work: transform payloads, enforce policies, sequence calls across services. That makes it powerful and makes it a single point of failure. When the ESB is slow, everything is slow. When it goes down, integration stops.
Deployment velocity is the other honest gap. Microservices teams ship independently because services are small and loosely coupled. SOA services tend to have shared dependencies and coordinated release cycles, which is appropriate for regulated environments but frustrating for teams that want to move fast.
Pros
- Business capabilities built once can be consumed by any application across the enterprise, which genuinely reduces duplication at scale
- The ESB handles protocol and format translation, so legacy systems can participate without being rewritten
- Strong governance model suits regulated industries where auditability and control matter
- Vendor-neutral by design; the interface contract is what matters, not the underlying implementation
Cons
- The ESB is both the architecture’s greatest asset and its most dangerous dependency. It concentrates risk and becomes a bottleneck under load
- Higher operational overhead than microservices, both in infrastructure and in the governance processes that SOA requires to function well
- Deployment cycles are slower because integration changes tend to have a broad blast radius
- Purpose-built for on-premises enterprise environments; adapts awkwardly to containerized, cloud-native deployment models
Best for: Large enterprises integrating heterogeneous system landscapes, regulated industries where governance and auditability are non-negotiable, and legacy modernization programs where the goal is to expose existing systems as services rather than replace them.
7. CQRS (Command Query Responsibility Segregation)
Command Query Responsibility Segregation (CQRS) is a software architecture pattern that splits the application into two completely separate pathways: a Command side that handles state mutations (writes) and a Query side that handles data retrieval (reads).
When combined with Event Sourcing, the application’s state is never overwritten; instead, it is stored as an immutable, chronological append-only log of events. You can use CQRS to split your read and write models using simple database replication without adopting full Event Sourcing. However, implementing full Event Sourcing introduces significant cognitive overhead; schema migrations for event stores (upcasting) require accuracy and precision.
How it works
To determine a user’s current account balance, the system plays back every deposit and withdrawal event from day one. To make reads fast, these events are projected asynchronously into a highly optimized, read-only database view.
Pros
- By separating read and write operations, you can scale each independently on demand.
- You can optimize read and write models for their specific purposes.
- CQRS allows for the use of different storage mechanisms for the read and write sides, depending on what is most appropriate for each operation’s performance and scalability needs.
- Separating commands and queries can enable more granular security policies, where read and write permissions are managed independently.
Cons
- Implementing CQRS can introduce additional complexity into the system, particularly in terms of maintaining two separate models and ensuring they are correctly synchronized.
- Depending on the synchronization mechanism between the read and write models, there might be a delay (eventual consistency) before the read model reflects the changes made in the write model.
- CQRS is a highly specialized architectural niche. General backend developers will struggle with the learning curve. You must target high-seniority backend talent with proven operational histories of building and running event-sourced systems in production.
Best for: Financial systems requiring full audit trails, high-read platforms (dashboards, reporting, search), complex domains where write and read models diverge significantly, and systems already using event sourcing.
8. Serverless Architecture (Function as a Service – FaaS)
Serverless architecture offloads all server management, provisioning, and infrastructure scaling to a cloud provider (e.g., AWS Lambda, Google Cloud Functions). Developers write code as discrete functions that execute in response to specific HTTP requests, database events, or file uploads.
Serverless eliminates idle compute infrastructure costs. However, it introduces vendor lock-in risks, “cold start” latencies on unexpected requests, and can become significantly more expensive than provisioned servers if your system maintains a massive, steady baseline of 24/7 traffic.
Look for Cloud Native Specialists. The challenge here is rarely writing the code; it is configuring the cloud ecosystem around the functions. Your engineers must be fluent in Infrastructure as Code (IaC) tools like Terraform or the Serverless Framework, and understand cloud security policies and distributed service limits.
How it works
Developers deploy their function code to a cloud provider’s serverless platform, which executes the functions in response to specific triggers like HTTP requests, file uploads, or database updates.
For example: A user requests a profile image. The cloud provider instantly spins up a micro-container running your specific function, executes the image resize logic, returns the result, and immediately shuts down the container.
Pros
- With micro-billing, you only pay for the compute time you consume, which can lead to significant cost savings, especially for applications with variable traffic.
- Developer Productivity: By removing the need to manage servers, developers can spend more time on building features and improving the application.
- The ability to automatically scale in response to traffic without the need for manual intervention ensures that applications remain responsive under varying loads.
- The cloud provider takes care of the infrastructure, reducing the need for DevOps and allowing smaller teams to manage larger infrastructures.
Cons
- When the system doesn’t call a function called for some time, there can be a delay (“cold start”) as the platform provisions a new instance. This can impact performance, particularly for latency-sensitive applications.
- The stateless nature of serverless functions can complicate the architecture of applications that require state persistence across function calls.
- If you design applications for a specific serverless platform, you may have to rework them to run on a different platform, creating potential vendor lock-in issues.
Use Cases
Serverless Architecture represents a paradigm shift in cloud computing, enabling developers to focus more on creating value through their applications rather than managing the underlying infrastructure.
- Web applications
- APIs
- Data processing
9. Hexagonal Architecture (Ports & Adapters)
Invented by Alistair Cockburn and highly aligned with Clean Architecture, Hexagonal Architecture isolates the core business logic of an application from external concerns like databases, web frameworks, email services, and UI components.
This means no databases, no HTTP, no message queues, no UI frameworks. The domain sits at the center; everything else connects to it through defined ports (interfaces) and adapters (implementations).
This is the architecture for teams that are serious about testability and long-term maintainability. Your domain logic can be tested in complete isolation, without spinning up a database or mocking an HTTP client.
This software architecture pattern guarantees your application’s core rules remain pure and completely testable without mocking complex infrastructure. You can change your database provider or move from a REST API to a GraphQL endpoint without altering a single line of business logic code.
How it works:
The core domain logic sits at the center, exposing abstract interfaces called Ports. External dependencies (like a PostgreSQL database, a Kafka adapter, or a third-party payment gateway) implement these ports via concrete wrappers called Adapters. Swapping the database means writing a new adapter, not touching the domain.
Pros
- Domain logic is completely decoupled from infrastructure — pure, fast unit tests
- Technology decisions (database, messaging, HTTP framework) become reversible
- Forces discipline in separating domain concepts from implementation details
- Highly maintainable for systems with complex, evolving business rules
Cons
- More upfront design work than most patterns; the port/adapter boundaries require careful thought
- Can feel like over-engineering for simple applications without meaningful domain complexity
- Requires developers who understand domain-driven design concepts; it’s not a beginner pattern
- The abstraction layers add indirection that can be disorienting until the team internalizes the model
Best for: Systems with complex, evolving domain logic; applications where testability is a first-class requirement; teams planning for long-term maintainability over initial speed.
What About the Client-Server Architecture?
Client-server is a distributed system architecture that focuses on how separate computers (clients and servers) communicate and share work over a network.
It’s considered a system architecture or communication model, distinct from software architecture patterns (such as MVC or microservices). The client-server model is primarily about networking aspects: deployment, the physical separation of network processes, and communication protocols between machines.
In short, a client-server architecture focuses on networks and the end devices within them, not on software.
How to Choose the Right Software Architecture Pattern
The single most common mistake I see engineering teams make is choosing an architecture pattern based on what’s popular, or what the most senior person on the team knows, rather than what the system actually needs. Microservices is not better than layered architecture. It’s more complex, more expensive to operate, and more powerful at scale. Those are not the same thing.
Here’s a decision framework based on the factors that actually matter:
| If your primary constraint is… | Consider |
| Team size is small (1–5 engineers) | Layered, MVC, Client-Server, Serverless |
| You need to ship fast and iterate | MVC, Layered, Serverless |
| Scalability is the primary concern | Microservices, EDA, Serverless, CQRS |
| You have complex business/domain logic | Hexagonal, CQRS, Layered |
| You’re integrating many existing systems | SOA, EDA |
| You need real-time data processing | EDA, Microservices |
| You need full audit trails/compliance | CQRS + Event Sourcing |
| You’re building extensible tools or platforms | Microkernel |
| Variable or unpredictable load | Serverless, Microservices |
| You have a large org with autonomous teams | Microservices, SOA |
A few practical rules:
- Don’t start with microservices unless you have the team to operate them. The break-even point where microservices complexity pays off is higher than most teams expect. If you have fewer than 15–20 engineers, a layered or modular monolith is usually the right answer.
- Serverless and EDA pair well. If you’re already thinking event-driven, serverless functions as consumers are a natural fit.
- MVC is not a legacy pattern. For most web applications, it’s still the correct choice in 2026.
- CQRS is a scalpel, not a default. Apply it where read/write complexity genuinely diverges. Don’t architect your whole system around it.
Use Our Decision Framework
Architecture pattern decision matrix mapping project size, team size, and scalability needs to recommended patterns
| Pattern | Project size | Team size | Scalability | Best for | Watch out for |
|---|
Software Architecture Patterns in the Age of AI
AI-integrated systems introduce a new set of architectural pressures that none of the classic patterns were designed for, and that’s worth acknowledging.
The dominant challenge is this: AI components (LLMs, vector databases, inference pipelines) have fundamentally different operational characteristics than traditional services. They’re stateful in unusual ways, they’re latency-heavy, they’re non-deterministic, and they often require retrieval pipelines (RAG architectures) that don’t map cleanly to standard request-response patterns.
What this means in practice:
- Event-driven architecture is increasingly relevant as AI inference gets integrated into async workflows — generate a summary when a document is uploaded, not when a user requests it.
- Hexagonal architecture is well-suited to AI integration because it keeps LLM calls behind port interfaces, making them swappable as the model landscape evolves.
- CQRS is gaining traction in AI-heavy systems, where the read model must serve AI-generated projections alongside traditional data.
- Serverless works well for inference endpoints with variable load — pay per inference call, scale to zero when idle.
The teams doing this well are not inventing new patterns. They’re applying existing patterns thoughtfully to components with new constraints.
Conway’s Law and Your Software Architecture
When selecting an architecture pattern, you must account for Conway’s Law, which says a company’s software architecture will inevitably mirror its internal communication and team structure. In fact, this principle influenced Domain-Driven Design.
For example, if your engineering group consists of 8 generalist developers in a single Slack workspace, adopting a Microservices architecture will fail. Forcing a fragmented network architecture onto that group creates friction.
On the other hand, if you have 4 isolated global engineering teams operating across different time zones, forcing them into a single, un-modularized Monolith will result in constant merge conflicts and stalled deployment pipelines.
Match your architectural blueprint to the team you have the budget, timeline, and capability to hire. If you want velocity without an infrastructure army, invest in a Modular Monolith or a highly structured MVC framework. If you are building for massive enterprise scale and possess the capital to hire deep infrastructure specialists, unlock the distributed power of Microservices and Event-Driven systems.
Hire the Fittest Engineer for Your Software Architecture and Business
The best thing about software architecture patterns is making development easier and faster than simply “building fast and fixing later”. There are many options, but keep in mind that a thorough evaluation of each pattern is key, as choosing the wrong one can cause delays and also result in software failure.
If you’re building event-driven software at scale, you’re not looking for someone who’s read about Apache Kafka. You’re looking for a senior who’s debugged a consumer lag problem at 2 am.
DistantJob has placed battle-seasoned architects who had to migrate clients from spaghetti code to a fully new software architecture.
If software architecture decides your next hire, we are here for that exact conversation. Let’s talk!
FAQ
Architecture patterns act at the system level; they define how major components of a system are organized and how they communicate. Design patterns operate at the code level — they solve specific implementation problems within a component (factory, singleton, observer, etc.). You use architecture patterns to structure your system; you use design patterns to structure your code within that system.
Microservices, Event-Driven, and Serverless offer the highest ceiling for scalability because they allow individual components to scale independently. The right answer depends on where your bottleneck is. If you need to scale reads independently of writes, CQRS gives you that. On the other hand, if you need to scale specific business functions without scaling the whole application, microservices. And, if your load is variable and unpredictable, serverless auto-scaling may be the most cost-effective choice.
Netflix is one of the most cited examples of microservices at scale. Their architecture uses thousands of microservices, an event-driven backbone for real-time data processing, and a heavily customized API gateway layer. They also developed several tools — Hystrix, Eureka, Zuul — specifically to manage the operational complexity that microservices introduced.
The short answer: when your team is large enough to operate microservices, and your system has genuinely independent scaling requirements across domains. If you have a team under 15 engineers, a well-structured modular monolith will almost always outperform a microservices architecture in terms of development velocity and operational stability. The monolith-to-microservices migration is a well-understood path; starting with microservices when you don’t need them is a much harder problem to unwind.
Layered (N-Tier) architecture remains the most widely used pattern across enterprise software. MVC is the most widely used pattern for web applications, specifically, largely because it’s the default structure of nearly every major web framework.




