While the terms Data Scientist (DS) and Machine Learning Engineer (MLE) are often confused, they have clear distinctions in their primary focus, responsibilities, skills, education, and career paths. Data Scientists focus on discovering insights from data and building predictive models, while ML Engineers deploy those models into production systems and ensure they run reliably at scale. In smaller companies and startups, people often get one of them to do both roles, so it’s not surprising that they are considered one and the same.
However, they couldn’t be more different.
Machine learning processes are cyclical; from the design and build of the predictive system (from the Data Scientist’s side) to the deployment, scalability, and continuous monitoring (from the Machine Learning Engineer’s side). The shift between one role and another is not always clear, and it often overlaps.
The handoff typically occurs when a model achieves target accuracy and business approval — Data Scientists handle research, experimentation, and model development (weeks to months), then ML Engineers take over for deployment, infrastructure scaling, and ongoing maintenance.
Let’s go into more detail by starting to define each role.
What is a Data Scientist?
A Data Scientist is a professional who guides strategic business decisions by analyzing data to extract meaningful insights, developing predictive systems through AI/ML models, and communicating their findings to stakeholders. They aim to convert complex business problems into manageable data-driven questions.
For example, a data scientist might see a pattern in consumer behavior and develop a machine learning algorithm to detect the best opportunities to sell products. Walmart’s Data Scientists discovered a curious correlation between hurricanes and Strawberry Pop-Tarts sales.
Data Scientist Responsibilities
A Data Scientist formulates a hypothesis according to their domain knowledge, then builds a Machine Learning algorithm to validate their ideas through data analysis. As soon as they see a pattern, they use that solution to predict future occurrences. Once the data scientist gets the best results, they prepare a presentation for the stakeholders.
- Domain Knowledge: A Data Scientist must understand other knowledge domains beyond data science itself.
- Problem Formulation: Translating a problem or hypothesis into a data science question that Machine Learning can answer. For example: “Customers with longer subscriptions are more likely to cancel their contracts. Why does that happen?”.
- Data Gathering and Cleaning: They collect raw data from various sources and ensure it is cleaned and prepared for analysis. Data preparation can take up 80% of a project’s time, according to Amazon.
- Exploratory Data Analysis (EDA): Data Scientists find patterns through statistical methods and visualizations, identifying errors, and validating hypotheses.
- Statistical Modeling and Algorithm Development: This is the time when data scientists choose the most appropriate Machine Learning model to make predictions and derive forecasts. Examples include “random forest”, “neural networks”, and “decision trees”. All these models predict data in different ways, and the data scientist chooses the one that performs best.
- Interpretation and Communication: As soon as they understand the model’s results, data scientists prepare a presentation to explain them and communicate their insights in layman’s terms to stakeholders.
Data Scientist Skills and Technologies
- Programming Languages: Python (most prominent), R (for statistical analysis and visualization), and SQL (for data querying). Java may also be used for data-intensive tasks.
- Job-Specific Skills: Data visualization (Tableau, Power BI), data mining, statistical analysis (hypothesis testing), exploratory data analysis (EDA), A/B testing, and strong communication and storytelling skills.
- Overlapping AI Skills and Tools: Machine Learning, AI concepts, Natural Language Processing (NLP), and Deep Learning. They use them more for analysis and insight extraction. PyTorch, TensorFlow, Scikit-learn, and Keras are also important.
- ML Algorithms and Methods: Data scientists have a more balanced distribution across methods, with a higher emphasis on NLP for text-based data analysis.
- Cloud Skills and Software: Microsoft Azure and AWS, focusing on data storage and processing. Less involved in containerization.
- Education and Background: Bachelor’s or master’s degrees in Data Science (most crucial), Mathematics, or Statistics. Some may have backgrounds in diverse fields like astrophysics or economics.

What is a Machine Learning Engineer?
Machine Learning Engineers are professionals who redesign predictive systems created by Data Scientists, and use software engineering to make them into practical, efficient, and scalable production systems. Their primary focus is on production and operation.
For example, Walmart machine learning engineers would rebuild the weather-sales predictive system and make it fully available for the company’s needs (scalability, easier interface, better UX, etc.).
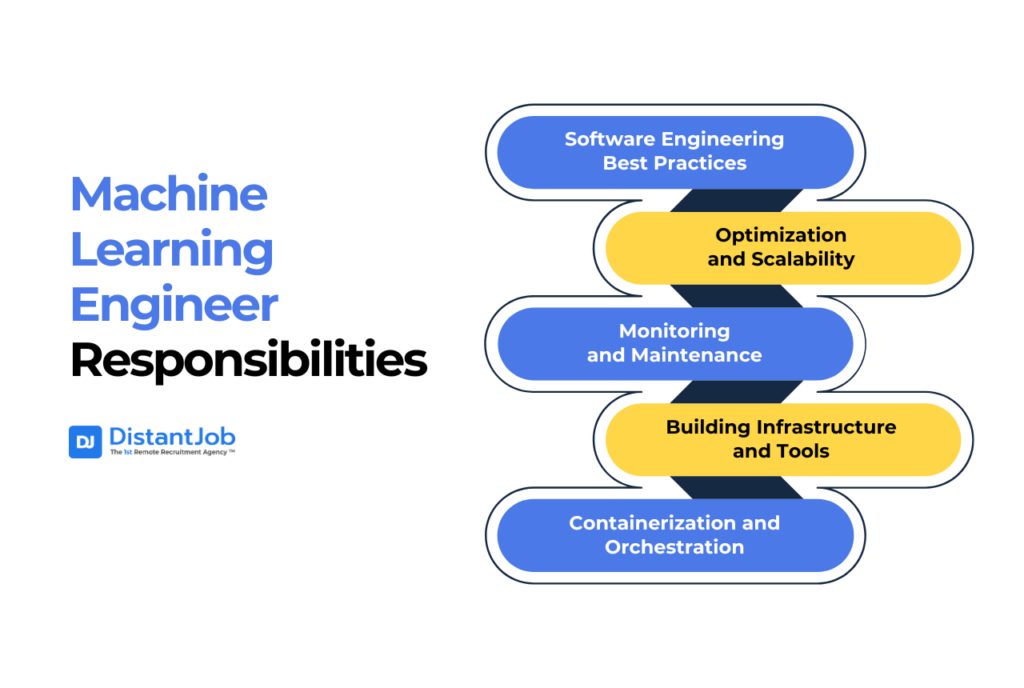
Machine Learning Engineer Responsibilities
ML Engineers take systems developed earlier by data scientists and deploy them into production environments. In other words, they take the system for mass production (for internal uses or sales, depending on the company or organization).
- Software Engineering Best Practices: Writing clean, efficient, and maintainable production-level code. The ML engineer must understand software engineering principles such as debugging, testing, and continuous integration.
- Optimization and Scalability: The solution must be optimized for performance, latency, memory, and throughput, and can handle large data volumes and real-time predictions.
- Monitoring and Maintenance: Continuously monitoring the solution in production to ensure performance doesn’t degrade, addressing troubleshooting issues, and managing updates.
- Building Infrastructure and Tools: Developing infrastructure and tooling to support machine learning pipelines, including automated training pipelines, data quality tests, and MLOps infrastructure for experimentation and model management.
- Containerization and Orchestration: The ML Engineer must employ technologies such as Docker and Kubernetes to containerize ML applications and manage their deployment across environments.
Machine Learning Engineer Skills and Technologies
- Programming Languages: Python is dominant, but proficiency in Java and C++ is highly valued for performance, scalability, and enterprise-level application development. SQL is also crucial for data pipeline management.
- Job-Specific Skills: Algorithm development, model optimization, Deep Learning (TensorFlow, PyTorch), Reinforcement Learning, Distributed Computing (Apache Spark), Model Deployment, Automation and Pipelining, and Containerization and Orchestration (Docker, Kubernetes).
- Overlapping AI Skills and Tools: Machine Learning, AI concepts, Natural Language Processing (NLP), and Deep Learning. However, MLEs require a deeper understanding and technical focus on building and deploying these systems. PyTorch and TensorFlow are dominant tools for both, but MLEs emphasize them more for production-ready systems. Scikit-learn and Keras are also important.
- ML Algorithms and Methods: MLEs show a higher need for advanced techniques, particularly in deep learning and computer vision, due to their role in building complex AI systems.
- Cloud Skills and Software: More extensive use of cloud platforms (AWS, Azure, GCP) and a stronger adoption of Docker and Kubernetes for scalable, reproducible ML environments.
- Education and Background: Advanced degree (bachelor’s or master’s, sometimes PhD) in Engineering, Computer Science, or specialized Machine Learning programs. They often have prior professional experience as software engineers.
Data Scientist vs. Machine Learning Engineer: Skills Comparison
Both Data Scientists and ML Engineers use Python and AI tools. Data Scientists focus on analysis, insight, and communication, utilizing statistics, visualization, R, and SQL. ML Engineers build, optimize, and deploy production systems, using advanced techniques and distributed computing. Here is a comparison sheet between Data Scientists and Machine Learning Engineers based on their analytical thinking, programming language, hard skills, methods, and tools:
| Feature | Data Scientist | Machine Learning Engineer | Overlapping Aspects |
| Analytical Thinking | Required | Required | Both roles require analytical thinking. |
| Programming Languages | Python, R, SQL, Java | Python, Java, C++, SQL. | Python is dominant for both, and SQL is crucial. |
| Job-Specific Skills | Data visualization (Tableau, Power BI), data mining, statistical analysis (hypothesis testing), exploratory data analysis (EDA), A/B testing, strong communication, and storytelling. | Algorithm development, model optimization, Deep Learning (TensorFlow, PyTorch), Reinforcement Learning, Distributed Computing (Apache Spark), Model Deployment, Automation and Pipelining, Containerization and Orchestration (Docker, Kubernetes). | |
| ML Algorithms & Methods | Balanced distribution across methods, higher emphasis on Natural Language Process | Higher need for advanced techniques, particularly in deep learning and computer vision. | |
| AI Skills & Tools | Use ML, AI concepts, NLP, and Deep Learning for analysis and insight extraction. PyTorch and TensorFlow, Scikit-learn, and Keras are important. | Deeper understanding and technical focus on building and deploying ML, AI concepts, NLP, and Deep Learning systems. PyTorch and TensorFlow (emphasized for production-ready systems), Scikit-learn, and Keras are also important. | Both utilize Machine Learning, AI concepts, Natural Language Processing (NLP), and Deep Learning. PyTorch and TensorFlow are dominant tools for both. Scikit-learn and Keras are also important for both. |
| Cloud Skills & Software | Preference for Microsoft Azure and AWS, focusing on data storage and processing. | More extensive use of cloud platforms (AWS, Azure, GCP), stronger adoption of Docker and Kubernetes for scalable, reproducible ML environments. | Both roles utilize cloud platforms; however, MLEs have a stronger adoption of containerization tools. |
| Education & Background | Bachelor’s or master’s degrees in Data Science (most crucial), Mathematics, or Statistics. Some may have backgrounds in diverse fields like astrophysics or economics. | Require an advanced degree (bachelor’s or master’s, sometimes PhD) in Engineering, Computer Science, or specialized Machine Learning programs. Prior professional experience as a software engineer. | Both roles may involve some level of programming and require analytical thinking. |
Data Scientist vs Machine Learning Engineer: The Handover Process
Data scientists develop predictive systems and hand them over to MLEs. This is done by a “contract” specifying model accuracy, latency, memory, framework used, and versions. The handover is a structured process that ensures MLEs have the necessary information for optimization, production, and deployment, allowing data scientists to focus on new use cases.
A structured handover contract ensures that Machine Learning Engineers have all the necessary information to work on the solution optimization, further experimentation, and deployment processes.
As stated before, in smaller companies (where the distinction is blurred), the professional is the same, so there is no handover. The data scientist goes “full-stack”, incorporating the machine learning engineer’s role.
Handover Participants
Data Scientists are primarily responsible for developing one or more candidate machine learning models. Machine Learning Engineers take these systems and prepare them for production, focusing on optimization, deployment, and ongoing monitoring.
Handover Information
When a Data Scientist hands over a system to a Machine Learning Engineer, the contract should specify various details:
- Model accuracy
- Latency (speed of predictions)
- Memory requirements
- Number of parameters
- The machine learning or deep learning framework used (e.g., PyTorch, TensorFlow)
- Program versions
- Model predictions
- Ground labels for the validation or test set
- Training, validation, and test datasets
- Model performance metrics (e.g., precision, sensitivity, F1-score)
- Agreed-upon metrics for optimization (e.g., latency, memory).
Data Scientist vs Machine Learning Engineer: Career Paths and Salary
Both data science vs machine learning engineer careers offer high earning potential and growth opportunities.
Salary
Machine Learning Engineers tend to have a slightly higher salary ceiling, with a larger percentage of positions offering around $128,769 on average (July 23, 2025, ZipRecruiter). For Data Scientists, the annual average is approximately $122,738 (July 23, 2025, ZipRecruiter).
Career Path
Data Scientists have opportunities to transition into more business-oriented roles like Principal Data Scientist or Chief Data Officer, while MLEs often progress deeper into technical specializations like Computer Vision Engineer or MLOps Engineer. Both can move into leadership, startups, or consultancy.
Demand
Both roles are in high demand. However, the demand for Machine Learning Engineers might grow by 40% from 2023 to 2027, according to the World Economic Forum’s 2023 Future of Jobs Report. That’s up to one million jobs, the largest growth of any occupation, says Fortune. The supply of skilled MLEs is currently limited compared to that of data scientists.
Meanwhile, the data scientist job market is currently experiencing both high demand and increased competition, particularly at the entry level. The U.S. Bureau of Labor Statistics projects a 36% growth in data scientist employment between 2023 and 2033, indicating a positive long-term outlook. The overall demand for data scientists remains strong due to the continued data growth and the need for data-driven decisions. However, the field is also maturing, leading to more specialized roles and increased competition for entry-level positions.
Transition
Data scientists can transition to Machine Learning Engineer roles due to overlapping skills. The requirements for them are strong software engineering skills, including optimized coding (e.g., C++), rigorous testing, and experience with deployment tools like Docker and Kubernetes. The best avenue for this transition is within their current employer, by assisting and collaborating with MLEs on projects.
Why do Data Scientists and ML Engineers often get their roles confused?
The terms “Data Scientist” and “Machine Learning Engineer” are relatively new and can be nebulous, with definitions varying significantly between companies, especially smaller businesses. In startups, a “full-stack data scientist” might handle both analytical and deployment tasks.
Some companies (small companies or those just starting to invest in data) might not have the budget or the need to contract an expert for each development phase. They search for professionals who might act at every stage of development for predictive systems. It happens similarly to the “full-stack”; when a company can’t afford back-end and front-end teams, they might employ a full-stack developer to do it all. All of this leads to job descriptions that mix requirements from both areas.
Conclusion
Data Scientists are the architects of insight, turning data into strategic business value through scientific exploration, modeling, and interpretation. Machine Learning Engineers, on the other hand, are the builders of robust systems, transforming them into scalable, production-ready solutions. While Data Scientists and Machine Learning Engineers share overlapping skills and may even function as one role in smaller organizations, they serve distinct purposes in the machine learning lifecycle.
As the field evolves and the demand for AI and data-driven decision-making accelerates, both roles will continue to grow—sometimes independently, sometimes together. But regardless of how the titles are used, the key takeaway is this: building successful machine learning systems requires both the strategic curiosity of a Data Scientist and the engineering discipline of a Machine Learning Engineer. One unlocks the potential of data. The other brings it to life.
And if you need a Data Scientist or a Machine Learning Engineer for your company, don’t forget to schedule a meeting with us. We are focused on headhunting the best candidate worldwide at the lowest cost: no hidden fees, no fine print. We handle the paperwork, the legislation, and the payment, while your remote hire does what really matters to your business: work. Talk to us today!




